Why Isn't My Brand Mentioned in ChatGPT? A Data-Backed Diagnostic Guide (2026)

TL;DR. Your brand isn't in ChatGPT because the model has no confident signal that you exist in your category. ChatGPT cites earned third-party sources - Wikipedia, Wikidata, comparison content, schema markup, llms.txt, verified social, and high-authority domains - over 93% of the time. If those signals are thin or absent, you are invisible. The fix is to systematically build the seven signals ChatGPT actually uses, in the right order. Run a free Brand Analyzer scan to see exactly which signals you're missing.
The short answer: why isn't my brand in ChatGPT?
Your brand isn't mentioned in ChatGPT because the underlying language model has no high-confidence association between your company name and your category. ChatGPT does not invent answers about brands - it composes them from training data and live retrieval, both of which rely on earned third-party signals. If your brand lacks a Wikidata entity, structured data, third-party citations, and a clear llms.txt file, the model will default to better-documented competitors. The fix is not to write more marketing copy on your own site. The fix is to build the seven external signals ChatGPT and every other answer engine measure against.
Why ChatGPT mentions some brands and not others
ChatGPT generates brand mentions from two sources. The first is its training data - the frozen snapshot of the public web the model learned from. The second is retrieval-augmented generation, where the system performs a live web search and incorporates the results into the answer. Both pathways reward the same thing: earned, third-party evidence that you exist and are credible inside a category.
The numbers make this concrete. A 2025 University of Toronto study (Chen et al., arXiv:2509.08919) found that ChatGPT cites earned third-party sources 93.5% of the time for well-known brand queries and 95.1% of the time for niche brand queries. In other words, your own marketing site is almost never the source. The model trusts the rest of the internet's description of you - not yours.
This matters more every quarter. Adobe's 2025 research found that 36% of consumers have discovered a new product or brand through ChatGPT. That is a discovery channel comparable to organic social. And eMarketer's 2026 outlook reports that 54% of U.S. marketers plan to implement generative engine optimization within 3 to 6 months - meaning the gap between brands that are cited and brands that are invisible is about to widen sharply.
Most teams misread the problem. They assume ChatGPT works like Google: write good content, get indexed, get surfaced. It doesn't. The model decides whether to mention you based on the density and consistency of external signals - the things you can't write yourself. This is why two competitors with identical revenue and traffic can have wildly different AI visibility. One has a Wikidata entity, a comparison page on a respected SaaS directory, and structured data. The other doesn't. The model only sees the first one.
The 7 signals ChatGPT actually uses to recognize your brand
The DataEase 7-Signal AI Visibility Framework is the diagnostic Brand Analyzer runs against any URL. Each signal is a specific, checkable artifact ChatGPT and other LLMs use to decide whether your brand exists and what it does. Build them in this order.
1. Wikipedia presence
What it is: A Wikipedia article about your company in English, ideally with a few inbound links from other Wikipedia pages. This is the highest-weighted earned signal in most LLM training data.
Why ChatGPT cares: Wikipedia is one of the most heavily sampled and trusted sources in every major language model's training corpus. Entries function as canonical entity definitions the model rarely contradicts.
How to check it yourself: Search "YourBrand site:en.wikipedia.org" on Google. If nothing comes back, you have no Wikipedia presence.
The fix: Most early-stage brands cannot pass Wikipedia's notability bar. Don't fake it - rejected pages hurt. Instead, earn coverage in independent secondary sources first (trade press, industry analysts, conference talks). Once you have three to five substantive third-party references, an experienced editor can draft a defensible page.
Brand Analyzer auto-checks this — the free audit confirms presence, links to your live article, and flags eligibility if you're not yet listed.
2. Wikidata entity
What it is: A structured entry in Wikidata (Q-number) that defines your company as an entity - founded date, headquarters, industry, key people, official website.
Why ChatGPT cares: Wikidata is the structured backbone behind Wikipedia and many knowledge graphs Google, Microsoft, and OpenAI ingest. An entity ID is how LLMs disambiguate your brand from companies with similar names.
How to check it yourself: Search your brand at wikidata.org. If no entry exists, the model has no entity to reason about.
The fix: Wikidata's notability bar is far lower than Wikipedia's. Create an entry with your official URL, founding date, industry classification, and any verifiable third-party references. Link the entity from your homepage with a sameAs property in your Organization schema.
Brand Analyzer auto-checks this — it returns your Wikidata Q-number and the populated property count, or tells you the entity is missing.
3. Tranco rank and domain authority
What it is: Your domain's standing on independent traffic and authority indexes. Tranco is the academic standard - a million-domain ranking aggregated across multiple sources and used widely in research.
Why ChatGPT cares: When the model has to choose which brand to cite in a category, domain authority is a tiebreaker. Brands inside the Tranco top 500,000 are dramatically more likely to be cited than those outside it.
How to check it yourself: Look up your domain at tranco-list.eu. If you don't appear, you're below the noise floor on traffic.
The fix: Domain authority is earned slowly. Prioritize substantive, linkable content over volume. One canonical post on a defensible topic in your category will earn more backlinks than ten generic posts. Pursue podcast appearances and guest essays on high-authority domains.
Brand Analyzer auto-checks this — your audit reports Tranco rank, estimated backlink count, and domain authority percentile against category peers.
4. Schema.org structured data
What it is: JSON-LD markup on your site that explicitly declares your Organization, Product, FAQPage, and Article entities to crawlers.
Why ChatGPT cares: Schema removes ambiguity. Instead of inferring what you do from prose, the crawler reads a structured statement. OpenAI's crawler, Google's AI Overviews indexer, and Perplexity's retrieval pipeline all consume schema directly.
How to check it yourself: Paste your homepage URL into Google's Rich Results Test. It will list every schema type the page declares - or report none.
The fix: Add Organization schema to your homepage with name, url, logo, sameAs (Wikidata, LinkedIn, Crunchbase), and description. Add Product or SoftwareApplication schema to product pages. Add FAQPage schema to any page with a question-and-answer section.
Brand Analyzer auto-checks this — it lists every schema type detected, missing recommended properties, and validation errors in one view.
5. Third-party citations (comparison content, listicles, reviews)
What it is: Mentions of your brand inside category roundups, comparison pages, "best of" lists, and independent reviews on domains you don't control.
Why ChatGPT cares: These are the literal text snippets the model retrieves to answer "what are the best tools for X." If you're not named in those documents, you cannot be in the answer. The Chen et al. study showed earned citations drove over 93% of brand mentions - this is that signal in practice.
How to check it yourself: Ask ChatGPT "what are the best [your category] tools" and read the cited sources. Then search those sources for your brand. If you're absent from the documents ChatGPT is reading, you are absent from the answer.
The fix: Identify the top 10 third-party listicles ChatGPT cites for your category. Reach out to each author with a substantive pitch: a unique angle, original data, or a use case their list is missing. Aim for inclusion in three within 90 days.
Brand Analyzer auto-checks this — it surfaces the third-party domains that mention you (and the ones that mention your top competitors but not you).
6. Verified social presence across major platforms
What it is: Active, verified profiles on LinkedIn, X, GitHub (where applicable), Reddit, and YouTube, each linking back to your official domain.
Why ChatGPT cares: Social profiles are entity-confirmation signals. They cross-reference your brand name with your domain, founding team, and product description across independent platforms. Inconsistent or missing profiles weaken the model's confidence that the brand exists as you describe.
How to check it yourself: Search your brand on each platform. Confirm the URL in the bio matches your canonical domain. Check that LinkedIn and X profiles are claimed and verified.
The fix: Claim every major platform even if you don't intend to post regularly. Use the same logo, description, and URL. Add a Reddit presence in the subreddit most relevant to your category - Reddit content is heavily weighted in retrieval and is now a confirmed Google partner for AI Overviews.
Brand Analyzer auto-checks this — it confirms each platform, flags inconsistencies between bios and your homepage, and detects unverified profiles.
7. llms.txt file
What it is: A plain-text file at yourdomain.com/llms.txt that describes your site, key resources, and canonical URLs in a format optimized for LLM ingestion. It is the AI-era equivalent of robots.txt, proposed in 2024 and now broadly adopted.
Why ChatGPT cares: When OpenAI's crawler, Perplexity, or any retrieval system fetches your site, llms.txt provides a curated map of what to index and how to describe you. It is the cheapest, fastest signal in this framework.
How to check it yourself: Visit yourdomain.com/llms.txt in a browser. If you see a 404, you do not have one.
The fix: Create a markdown-formatted llms.txt at your domain root. Include a one-line site description, links to your most important pages (product, pricing, documentation, key blog posts), and a short canonical brand description. Aim for 200 to 600 words.
Brand Analyzer auto-checks this — it fetches your llms.txt, validates the structure, and shows what an LLM would read.
How to diagnose all 7 signals in 60 seconds
Running each of the seven checks manually takes a focused team most of a working day. Brand Analyzer runs all seven in parallel against any URL and returns the full report in under 60 seconds, with no signup. Each signal is scored, flagged with evidence inline, and ranked by impact-per-effort against your specific category peers.
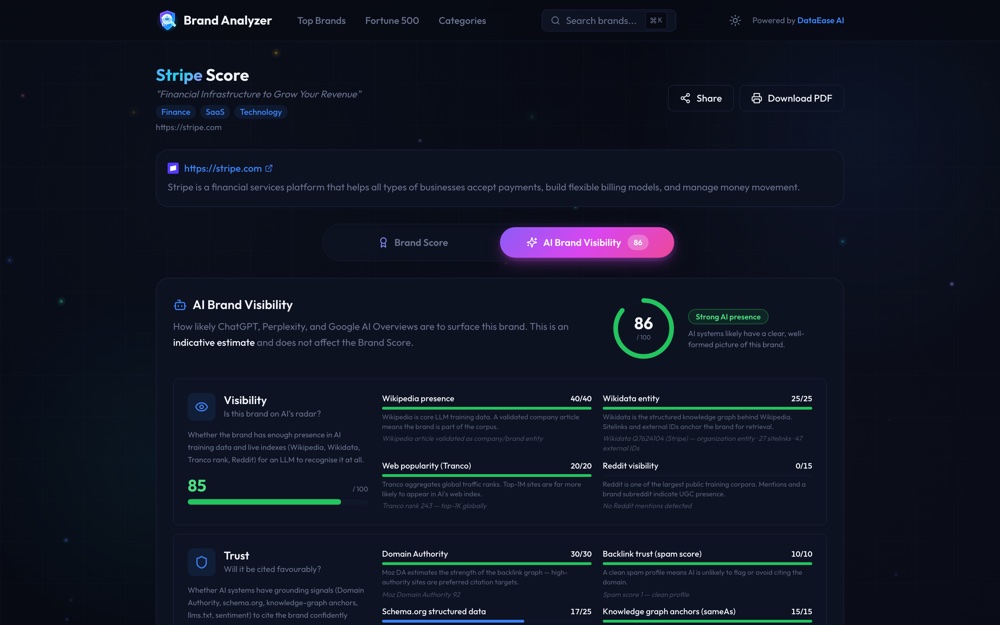
The report includes a side-by-side comparison against two competitor URLs of your choice. This is the fastest way to surface the specific signals your competitors have that you don't - the exact gaps that determine which of you ChatGPT cites. Run a free audit and use it as the working document for the fix order below.
The fix order: what to prioritize if you're scoring low
Most teams that read about AI visibility chase the most prestigious signal first - a Wikipedia entry. That is the wrong starting point. Wikipedia takes months, requires earned coverage you don't yet have, and is the lowest-impact fix per hour for a brand still missing the basics. Build in this sequence instead.
Week 1 (free, immediate impact). Three actions, all under your direct control. First, ship schema.org markup. Organization schema on the homepage, Product or SoftwareApplication on product pages, FAQPage on any Q&A content. This is a one-day engineering task that immediately changes how every crawler reads your site. Second, publish an llms.txt at your domain root - 30 minutes of work. Third, claim and verify every major social profile with consistent bio, logo, and canonical URL. Together, these three close the gap on three of the seven signals in a single week, at zero spend.
Weeks 2 to 4 (free, slower). Create your Wikidata entity. The notability bar is low, but the process requires a few independent references and a careful first edit to avoid rejection. While you wait for review, expand llms.txt with your top 20 pages and short descriptions. Audit your existing third-party mentions - directory listings, podcast appearances, guest posts - and ensure each one links to your canonical domain with consistent brand name spelling.
Months 2 to 3 (earned, highest leverage). Pursue third-party comparison content placements. Identify the 10 listicles ChatGPT actually cites for your category (you can see this in Brand Analyzer's competitor comparison view). Pitch each author with a specific, substantive angle - original data, a missing use case, or a customer story. Aim for three placements. If your brand passes the bar, begin the Wikipedia process by working with an experienced editor; do not write a self-promotional draft.
Ongoing. Compound authority. Publish original research and category-defining content quarterly. Pursue podcast appearances on shows in your category. Build a Reddit presence in the subreddit your buyers actually use - thoughtful, non-promotional contributions over months. Re-run your Brand Analyzer audit monthly and act on whichever signal scored lowest. AI visibility is not a one-time fix; it is a recurring operating discipline, the same way SEO became one a decade ago.
This is the order Brand Analyzer recommends based on impact-per-effort. Run an audit to get a personalized sequence calibrated to your specific gaps and competitor set.
Frequently asked questions
How long does it take for ChatGPT to start mentioning my brand after fixing these signals?
Retrieval-based mentions appear fastest. If your fixes target ChatGPT's live web retrieval - schema markup, llms.txt, fresh third-party citations - you can see new mentions within two to six weeks. Training-data mentions are slower, since they only land when the next model is trained on a snapshot of the public web. Most teams see meaningful movement on retrieval queries within 30 to 60 days and durable training-data presence within 6 to 12 months of consistent signal building.
Does paying for ads in ChatGPT help my organic mentions?
No. As of 2026, ChatGPT does not run a paid placement program that influences which brands appear in organic answers. The OpenAI partnerships and shopping features that exist are clearly labeled and separate from the model's recommendation behavior. Paid ads on Google or LinkedIn do not move the needle on ChatGPT either - the model weighs earned third-party signals, not ad spend. Organic AI visibility is entirely a function of the 7 signals covered in this guide.
Is GEO (Generative Engine Optimization) the same as SEO?
No. SEO optimizes ranked lists of links. GEO optimizes the answer itself - what the AI says when a user asks about your category. SEO rewards click-through-rate, backlinks, and keyword targeting. GEO rewards being the source the model trusts enough to cite, name, or recommend. The two overlap on technical fundamentals like schema and crawlability, but the strategic surface is different: GEO is about being inside the answer, not adjacent to it.
Can I check my brand visibility for free?
Yes. Brand Analyzer scores any URL across all seven signals in the 7-Signal AI Visibility Framework plus an AI Brand Visibility audit. The tool requires no signup, runs in under 60 seconds, and shows the underlying evidence inline - Wikipedia presence, Wikidata entity, Tranco rank, schema coverage, social verification, and llms.txt detection. The free report includes a prioritized fix list.
Does ChatGPT use real-time data or only training data?
Both. ChatGPT answers come from two sources. The first is the model's training data, a frozen snapshot of the public web up to its cutoff date. The second is retrieval-augmented generation, where ChatGPT performs a live web search through Bing or its own crawler and incorporates the results. When a user asks about a brand, the system often blends the two - training-data context plus fresh retrieval. Both sources matter for visibility, which is why the 7-Signal Framework covers both static signals (Wikipedia, Wikidata) and live signals (llms.txt, schema, third-party citations).
Why does my competitor get mentioned but I don't, even though we're similar size?
Similar revenue does not equal similar AI visibility. The competitor almost certainly has stronger earned signals - a Wikidata entity, a few third-party comparison pages, schema markup, or a Wikipedia entry. ChatGPT does not weigh ARR or employee count. It weighs the density and quality of third-party references that describe your category and confidently associate your brand with it. A Brand Analyzer side-by-side scan against your competitor will show exactly which signals they have that you don't.
Do I need a Wikipedia page to be mentioned in ChatGPT?
No, but it helps. Wikipedia is one of the most heavily weighted sources in LLM training data, so brands with entries enjoy a structural advantage. Smaller brands without a Wikipedia entry can still earn citations through a Wikidata entity, third-party comparison content, verified social profiles, and a maintained llms.txt file. Brands that meet Wikipedia's notability bar should pursue it. Brands that don't should compound the other six signals instead - the framework is designed so the bottom six signals, built together, approximate the lift of a Wikipedia entry.
Bottom line
If you asked ChatGPT about your category and your brand wasn't there, the problem is not your product, your marketing copy, or your traffic. The model has no confident signal that you exist. ChatGPT and every other answer engine compose brand mentions from earned, third-party evidence - and over 93% of citations come from those sources, not from your own site. The fix is the 7-Signal AI Visibility Framework: Wikipedia, Wikidata, Tranco rank, schema, third-party citations, verified social, and llms.txt - built in priority order, starting with the week-one moves that cost nothing and ship the same day. Run a free Brand Analyzer audit, see your scores against your competitors, and start with the lowest signal. The brands that win this channel over the next two years will be the ones that treated AI visibility as an operating discipline, not a one-time campaign.
How to cite this guide
DataEase AI. Why Isn't My Brand Mentioned in ChatGPT? A Data-Backed Diagnostic Guide (2026). DataEase AI Blog, May 22, 2026. https://blog.dataease.ai/why-isnt-my-brand-in-chatgpt/. Methodology: the DataEase 7-Signal AI Visibility Framework, applied via Brand Analyzer (brands.dataease.ai). Related reading: What Is Brand Presence?, SaaS Brand Audit: Bottom Quartile Patterns, and Brand Identity on a Budget.